The latest Spark2 versions are capable of running Python 2.7+ or 3.4+ code (Python 2.6 support was removed from Spark 2.2.0).
In some situations, PySpark uses Python 2.7 in both the driver and the workers, as this is usually the default Python version that is shipped in most enterprise Linux distributions.
What if we want to use a different Python version in Spark?.
Fortunately, it is possible to install and use multiple versions of Python in Spark. It is as simple as deploying the required version of Python in both the node that runs the driver program, as well as in the master node and in all the executor nodes, and then use a Spark environment variable to specify which version to use.
To deploy the required Python version we can, for example, install Anaconda3 on the node where we have installed the Spark client as well as on all the Spark executor nodes in our cluster (in this case I have installed Anaconda3 on all the nodes under /opt/anaconda3).
The installation instructions for a multi-user Anaconda Linux environment are here.
In my case I followed these steps:
On all the Spark executor nodes and the Spark client node (i.e. an edge node) I did run
# wget https://repo.anaconda.com/archive/Anaconda3-2019.03-Linux-x86_64.sh
# chmod +x Anaconda3-2019.03-Linux-x86_64.sh
# ./Anaconda3-2019.03-Linux-x86_64.sh
Welcome to Anaconda3 2019.03
Do you accept the license terms? [yes|no]
[no] >>> yes
Anaconda3 will now be installed into this location:
/root/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/root/anaconda3] >>> /opt/anaconda3
PREFIX=/opt/anaconda3
installing: python-3.7.3-h0371630_0 ...
Python 3.7.3
installing: conda-env-2.6.0-1 ...
installing: blas-1.0-mkl ...
installing: ca-certificates-2019.1.23-0 ...
[...]
installation finished.
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
[no] >>>no
[...]
Thank you for installing Anaconda3!
# chgrp -R hadoop /opt/anaconda3
# chmod 770 -R /opt/anaconda3
On the Spark client node (i.e. an edge node) I did run
# usermod -G hadoop -a raul
# su - raul
$ source /opt/anaconda3/bin/activate
$ conda init
no change /opt/anaconda3/condabin/conda
no change /opt/anaconda3/bin/conda
no change /opt/anaconda3/bin/conda-env
no change /opt/anaconda3/bin/activate
no change /opt/anaconda3/bin/deactivate
no change /opt/anaconda3/etc/profile.d/conda.sh
no change /opt/anaconda3/etc/fish/conf.d/conda.fish
no change /opt/anaconda3/shell/condabin/Conda.psm1
no change /opt/anaconda3/shell/condabin/conda-hook.ps1
no change /opt/anaconda3/lib/python3.7/site-packages/xontrib/conda.xsh
no change /opt/anaconda3/etc/profile.d/conda.csh
modified /home/raul/.bashrc
==> For changes to take effect, close and re-open your current shell. <==
$ source ~/.bashrc
To tell Spark that we will use the Python3 version shipped with Anaconda3, we simply have to set the environment variable PYSPARK_PYTHON in the client node that submits the Spark job (that is the node where the spark-submit is executed from, or where the PySpark Shell is started).
This can be easily achieved by adding the following to the .bashrcof the user’s profile:
export PYSPARK_PYTHON="/opt/anaconda3/bin/python3"
For more information take a look at the official Spark documentation here.
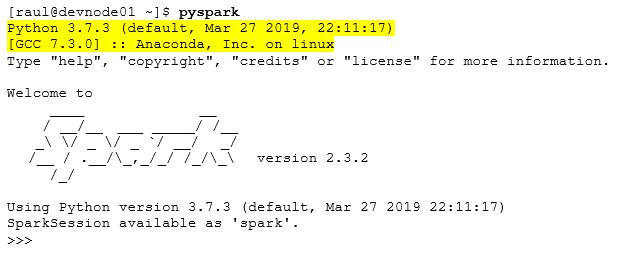
Following our example, once Anaconda3 has been installed in the required nodes and aforementioned environment variable has been set, we can check the result by starting the PySpark shell (do not forget to do a source ~/.bashrc before starting PySpark to reload the user’s profile):