
Este post expone las motivaciones y beneficios de utilizar una solución de almacenamiento compartido y alto rendimiento bajo protocolos abiertos, como es ONTAP de NetApp, para entornos de Analíticas de Nueva Generación.
To read a (bad) English Google-translated version of this post click here.
La comunidad de Big Data Analytics ha venido utilizando tradicionalmente sistemas de almacenamiento específicos basados arquitecturas scale-out, diseñados para entregar un elevado ancho de banda, y orientados a escalar y soportar el análisis de enormes conjuntos de datos. Estos sistemas, desplegados sobre hardware commodity, incluyen una serie de mecanismos que les dotan de una elevada tolerancia a fallos, algo sumamente necesario en este tipo de arquitecturas formadas por nodos (o servidores) con gran cantidad de discos internos que forman o se presentan como un sistema de ficheros distribuido.
HDFS es uno de estos ejemplos.

Uno de problemas a los que se enfrenta un sistema distribuido (sea de cómputo o de almacenamiento) son los efectos adversos e imprevisibles derivados del rendimiento y la latencia de la red de comunicaciones, así como la complejidad que implica una paralelización efectiva y eficiente. Para mitigar o evitar este tipo de circunstancias, HDFS cambió el paradigma en el modelo de acceso y procesamiento al dato ya que proporcionaba una serie de interfaces de localización que permitían “mover la computación donde se encuentran los datos” y no al revés como tradicionalmente se venía haciendo. Esto ha venido repitiéndose como un mantra desde entonces y ha hecho que cale la percepción de que una solución de almacenamiento compartido tradicional (como los sistemas de almacenamiento centralizados basados en NFS) era demasiado lenta y poco escalable para soportar este tipo de cargas de trabajo (y razón no faltaba en la época cuando Hadoop vió la luz).
Sin embargo con el paso del tiempo las cargas de trabajo en el mundo de la analítica del dato de nueva generación han ido evolucionando y ya no solamente es necesario un elevado ancho de banda para soportar las analíticas orientadas a batch o los ETLs y las agregaciones masivas sino que también es necesario soportar modelos de procesamiento en tiempo real, en modo interactivo, así como soportar los flujos de trabajo que requieren las iniciativas de Inteligencia Artificial y sus pipelines de datos completos de principio a fin. Esto cambia radicalmente el perfil del almacenamiento ya que estas nuevas necesidades requieren sistemas de almacenamiento de muy baja latencia, capaces de procesar mucha E/S aleatoria además de mantener elevadas tasas de ancho de banda (E/S secuencial), sin olvidar la escalabilidad en capacidad y permitiendo además la E/S concurrente sin penalización por el tipo de operación a miles de millones de ficheros, objetos y datos estructurados, semiestructurados o no estructurados.
Adicionalmente se empiezan a considerar seriamente aspectos que se tenían algo descuidados hasta entonces:
- La variedad de sistemas y soluciones de procesamiento y tratamiento del dato que se utilizan en un pipeline que ha ido evolucionando con el tiempo ha creado silos de datos dentro del propio Datalake que añaden complejidad a su gestión y que dificultan el acceso compartido de la información en entornos colaborativos (teniendo que copiar y mover datos de un estadio o sistema a otro para poder realizar esta tarea).
- El escalado se convierte en ineficiente e inflexible ya que el modelo de cómputo y almacenamiento fuertemente acoplado que utilizan estas arquitecturas obliga, en ocasiones, a consumir cómputo cuando solo se requiere ampliar la capacidad de almacenamiento y viceversa.
- El backup, que no protección, del dato es un auténtico olvidado. En entornos académicos o en proyectos de prospección y validación de ideas puede ser perfectamente válido no adoptar políticas de backup o respaldo y recuperación de la información, pero en entornos empresariales esto es inasumible. Si parte de nuestro Datalake (o incluso todo) se ha convertido en la fuente de información primaria para nuestra inteligencia de negocio es igualmente importante adoptar medidas para contar con un respaldo del dato válido y estar listos para una posible recuperación frente a una contingencia o desastre.
¿Porqué un almacenamiento empresarial como ONTAP?
NetApp es el líder mundial indiscutible en almacenamiento compartido empresarial gracias a su ADN. De hecho la compañía nació en 1992 como resultado de investigaciones y patentes específicas sobre un sistema operativo (Data ONTAP) que empleaba un sistema de ficheros muy eficiente y escalable (WAFL) con funcionalidades de protección y respaldo del dato muy adelantadas para aquella época (RAID-DP, snapshots, etc.) y que además utilizaba NFS. La gran ventaja que ofrece NFS es que es un estándar abierto soportado por infinidad de clientes y dispositivos de manera nativa (desde tabletas y dispositivos de IoT hasta servidores y clientes Unix, Linux y Windows). Con el paso del tiempo, ONTAP y WAFL han ido evolucionando convirtiéndose en una solución elástica que permite el crecimiento en horizontal y en vertical, y adoptando nuevos protocolos de almacenamiento (añadiendo objeto/S3 recientemente) bajo su concepto de arquitectura unificada (fue el inventor de este modelo) y siendo pionero en incorporar nuevas tecnologías de almacenamiento (Flash, NVMe, etc.) y de conectividad (100GbE, RDMA, etc.) que han equilibrado la balanza “cómputo-red-almacenamiento” eliminando las diferencias que había entre éstas y que hicieron muy útiles y facilitadoras arquitecturas como Hadoop.
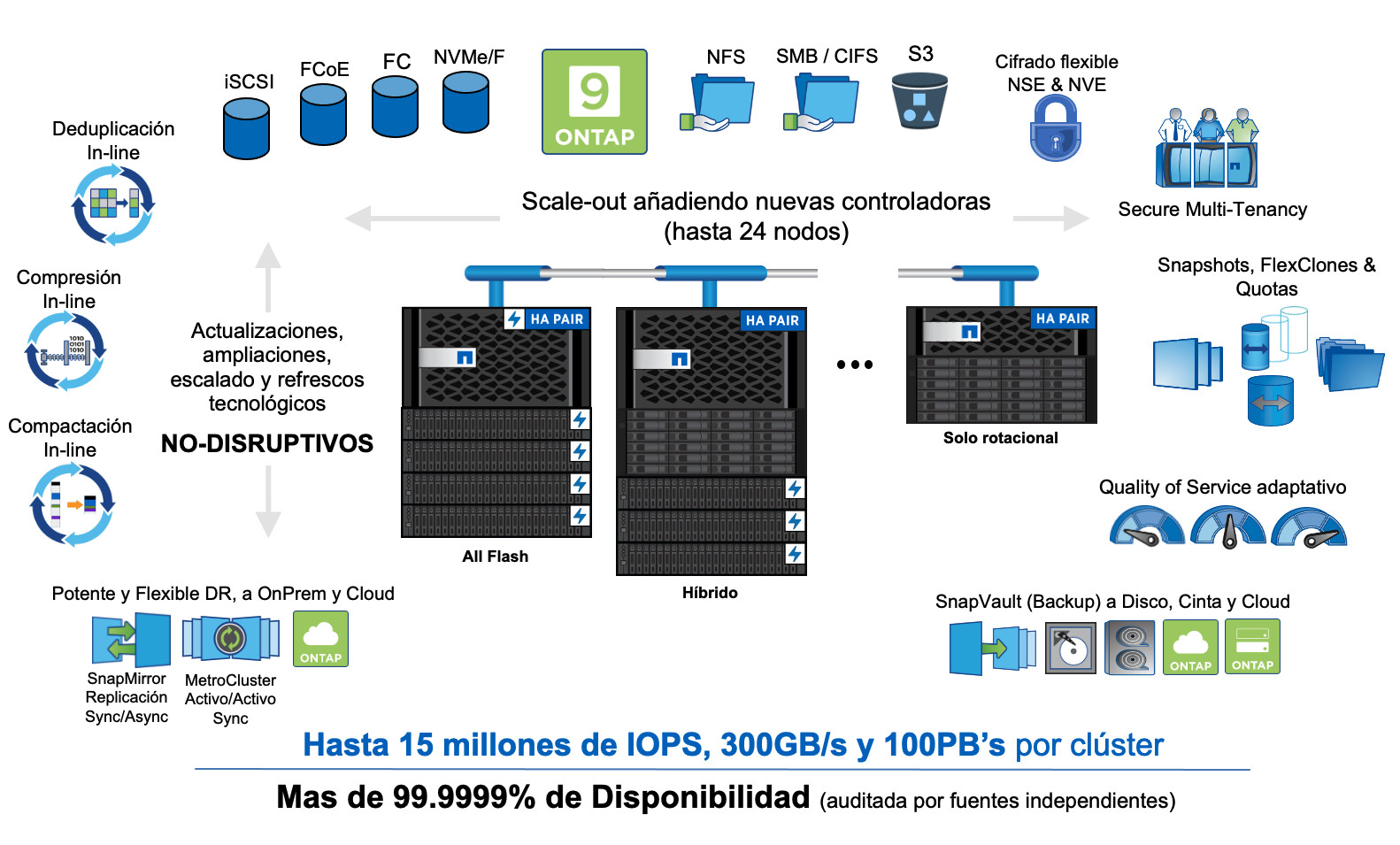
En la actualidad un clúster de ONTAP puede escalar hasta 24 controladoras o nodos y es capaz de ofrecer cientos de GB/s de ancho de banda, decenas de millones de IOPs de rendimiento a muy baja latencia y cientos de Petabytes de capacidad. De hecho, uno de los aspectos más importantes de la arquitectura de ONTAP es que ha roto con ese mantra de décadas pasadas: ya no es más rápido mover el cómputo hacia el dato, por fin nos podemos permitir seguir moviendo el dato hacia el cómputo y beneficiarnos de bastantes de ventajas y funcionalidades que hasta ahora no eran posibles de otra manera.
Un pipeline de datos de Analytics/AI de principio a fin con NetApp podría ser, a muy alto nivel, como sigue:
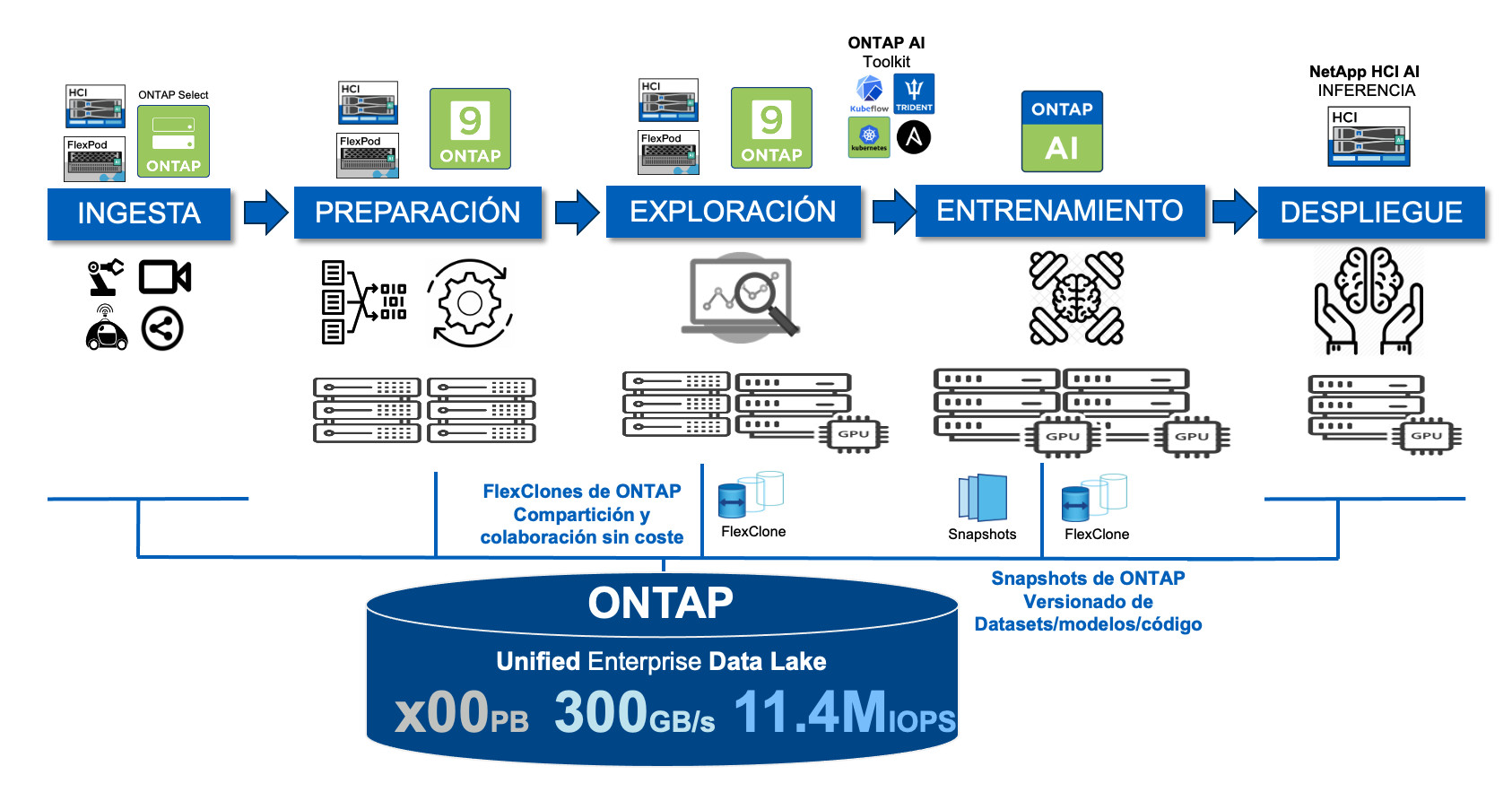
¿Qué beneficios aporta ONTAP?
Diseñado para consolidar todo tipo de cargas de trabajo.
Una de las cosas que gestiona muy bien ONTAP son los metadatos y su escalabilidad y rendimiento con miles de millones de ficheros. De hecho, gracias a su tecnología de FlexGroups, es capaz de paralelizar las operaciones de metadatos tan frecuentes y necesarias en todo sistema de ficheros distribuido. De esta manera ONTAP no solo es capaz de proporcionar excelentes anchos de banda en operaciones secuenciales sino que además su rendimiento destaca sobre el resto de las soluciones incluso con ficheros muy pequeños y bajo entornos que requieren acceso aleatorio con baja latencia (como suele ocurrir en procesos de entrenamiento e inferencia de modelos de Inteligencia Artificial). Esto hace que ONTAP sea un candidato ideal para unificar y consolidar los procesos que ocurren en el pipeline de datos y que corresponden con cargas de trabajo mixtas (unas requieren acceso secuencial, otras aleatorio, otras generan gran cantidad de operaciones de metadatos en el backend, etc.)
Permite desacoplar el cómputo del almacenamiento.
Este es otro de los beneficios clave para poder obtener eficiencia operacional. Al tener una infraestructura de almacenamiento compartido con ONTAP permite el escalado independiente de las capas de cómputo y almacenamiento permitiendo que éstas crezcan dependiendo de la demanda o necesidad. Ésta es una de las “recetas mágicas” de los híper-escalares del la nube. Otro de los efectos beneficiosos de este desacople es que simplifica la administración, especialmente en la parte del almacenamiento (pasamos de gestionar servidores con hardware commodity dispuestos en una arquitectura distribuida basada en JBODs a gestionar una infraestructura empresarial centralizada, mas densa, fiable y altamente escalable y sin las limitaciones en metadatos o posibles cuellos de botella de los nodos de metadatos/namenodes/etc.).
Almacenamiento persistente para arquitecturas de nueva generación.
El auge del Cloud Computing ha hecho que se replanteen muchos de los conceptos y arquitecturas que se venían utilizando en despliegues On-Prem. Empieza a ser ya muy común el adoptar arquitecturas de cómputo ligeras y muy escalables, que sean autoadaptables y elásticas, y que estén fuertemente integradas con las metodologías de DevOps y estén orientadas a microservicios. Sin duda los contenedores y tecnologías como Kubernetes son los grandes facilitadores de este cambio de paradigma. Hace tiempo que están disponibles Operadores de K8s para aplicaciones y entornos como Apache Spark, Apache Airflow, Cassandra, ElasticSearch, Flink, Kafka, RabbitMQ, Redis, MongoDB, MySQL, Neo4J, TensorFlow, por nombrar solo algunos. Uno de los problemas fundamentales de este tipo de arquitecturas es la persistencia en los datos (los contenedores nacen como entidades efímeras) y aquí es donde ONTAP, de nuevo, brilla al proporcionar un orquestador que se integra en K8s y Docker y que permite automatizar la gestión del almacenamiento persistente para los contenedores (Trident de NetApp) tanto para almacenamiento basado en bloque como en fichero.
Completamente conectado con la nube.
Desde hace años ONTAP ha evolucionado sus tecnologías de movimiento, copia y sincronización de datos para que alcancen la nube de los principales híper-escalares. Hoy, hay servicios de almacenamiento de datos de ONTAP (Cloud Volumes ONTAP, Cloud Volume Services, Azure NetApp Files, etc.) en Google, AWS y Azure que además se complementan con otros servicios gestionados por NetApp que permiten mover aplicaciones y datos entre sistemas ONTAP On-Prem y estos servicios de datos en la nube. Esto ha permitido que numerosos clientes adopten aproximaciones multi-cloud híbridas o que incluso ya hayan mejorado sus procesos de analytics en la nube gracias a ONTAP. Una interesante comparativa de costes y rendimiento bajo Apache Spark la podéis encontrar en este enlace.
Funcionalidades de gestión y protección del dato únicas en la industria.
ONTAP lleva proporcionando funcionalidades avanzadas de gestión del dato desde hace décadas y muchas de ellas pueden ser muy útiles en el campo de ciencia de datos o analytics. Gracias a sus funcionalidad de snapshots es posible tener copias instantáneas de un filesystems sin penalización en el rendimiento y eficientes en espacio (solo ocupan el espacio que necesitan las modificaciones o cambios en los datos) lo que permite emplearlas como puntos de recuperación o respaldo o incluso control de versiones de conjuntos de datos, código, etc. Su funcionalidad de FlexClone permite hacer clones instantáneos, sin penalización de rendimiento y también eficientes en espacio para generar copias eficientes de conjuntos de datos o código que puede ser compartido y re-instanciado en entornos de pre-producción y desarrollo evitando lentos procesos de copia y duplicidades en las capacidades de almacenamiento. Su funcionalidad de SnapVault permite implementar una solución de respaldo y recuperación de datos a otra instancia o sistema ONTAP (Disk-To-Disk backup) capaz de soportar grandes cantidades de datos y larguísimos periodos de retención. Además estas tecnologías se complementan con las técnicas de eficiencia adicionales de ONTAP como son la compactación, compresión y deduplicación inline. Por último, gracias a ONTAP es posible establecer sencillos escenarios de recuperación frente a desastres incluso automatizando el failover y haciéndolo transparente a las aplicaciones gracias a sus funcionalidades de SnapMirror y MetroCluster.
Almacenamiento compartido abierto y multiprotocolo.
Todos los entornos, sistemas y clientes empleados en Big Data Analytics e Inteligencia Artificial soportan de manera nativa los protocolos NFS y S3 que ONTAP proporciona. Esto significa que a la hora de integrar una solución ONTAP en nuestro datalake no es necesario reescribir código y cambiar las aplicaciones. Además, el soporte multiprotocolo de ONTAP permite compartir información, filesystems, conjuntos de datos, etc. con otro tipo de clientes y aplicaciones que utilicen SMB y CIFS eliminando silos de datos y facilitando la colaboración (algo fundamental en data science). A modo de ejemplo, Apache Spark y Hadoop MapReduce pueden leer y escribir a filesystems compartidos por NFS en ONTAP de manera transparente y con un adecuado rendimiento utilizando llamadas estándar del sistema de archivos y aprovechando el cliente NFS del kernel sin necesidad de reconfiguración; de la misma manera ocurre con el cliente nativo S3 que se incorpora en estos entornos y que permite la E/S a buckets S3 de ONTAP.
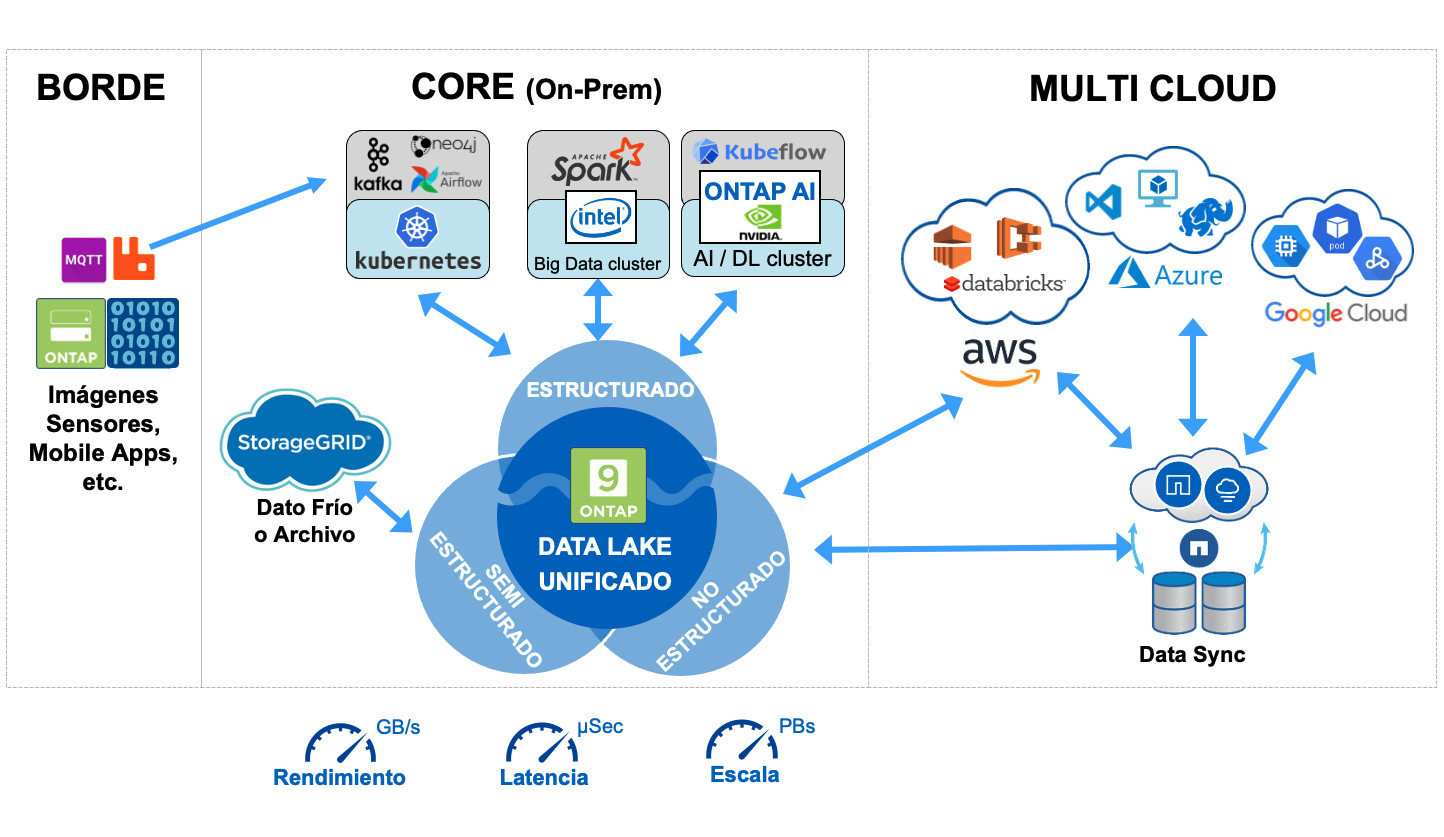
En los próximos posts veremos algunos ejemplos de cómo integrar y utilizar ONTAP en distintos entornos de Big Data Analytics.