
En este post vamos a ver cómo utilizar StorageGRID de NetApp como almacenamiento de datos para entornos Hadoop y Spark y, así, desacoplar el cómputo del almacenamiento en nuestra plataforma de analytics. En la actualidad, el protocolo S3 se ha convertido en un estándar de facto gracias a la explosión de la computación en la nube ya que es ahí donde nacieron numerosas iniciativas de analytics que hoy son referencia y donde el cómputo consume almacenamiento de objetos directamente.
To read a (bad) English Google-translated version of this post click here.
StorageGRID de NetApp
StorageGRID es la solución de almacenamiento de objeto definida por software de NetApp que, además, lleva siendo nombrada como líder de mercado durante dos años consecutivos por los analistas.
StorageGRID puede implementarse con appliances específicos hardware suministrados por NetApp (la series SG60xx y SG57xx) o bién puede desplegarse en máquinas virtuales bajo VMware o en servidores commodity (bare-metal). Es compatible con la API de objetos Simple Storage Service (S3) de Amazon y, además de ser altamente escalable (un GRID puede crecer en cientos de nodos y albergar varios cientos de miles de millones de objetos) y ofrecer unos niveles de protección y resiliencia únicos en la industria, permite crear espacios de nombres únicos geo-redundantes entre múltiples sites (hasta 16 sites dispersos). Otro de los importantes diferenciadores de StorageGRID es su potente ILM que permite establecer distintos SLAs mediante políticas de ciclo de vida del dato que optimizan la ubicación del mismo en función de condicionantes predefinidos por el administrador.
StorageGRID es una solución que lleva en el mercado más de una década y actualmente se encuentra en su undécima generación. La release 11.4 que salió en verano de 2020 trajo importantes mejoras en la parte de rendimiento de los appliances (un simple nodo SGF6024 es capaz de sostener más de 3GB/s) y la incorporación de QoS avanzado.
En éste enlace se puede encontrar la documentación oficial, hojas de producto, características y documentación técnica adicional.
Configurando el acceso a StorageGRID desde Hadoop y Spark
Una de las maneras más sencillas es utilizando los siguientes parámetros/valores y añadiéndolos al “core-site” dentro de la configuración de HDFS:
fs.s3a.endpoint el Load Balancer EndPoint de StorageGRID al que conectarse
ejemplo: s3.ntap.demolab.es:10443
fs.s3a.access.key clave de acceso
ejemplo: ERT45T78JHGBZXCBVWRT
fs.s3a.secret.key clave de autenticación para la clave de acceso
ejemplo: 8IAzf0bsZzgwed/a7Cthq8fh2yIu/xJp5zfN/8NbY
fs.s3a.buffer.dir directorio local donde almacenar temporalmente las subidas
ejemplo: /tmp
fs.s3a.connection.ssl.enabled habilita o deshabilita SSL
ejemplo: false (para deshabilitar cifrado y mejorar el rendimiento)
fs.s3a.impl la clase que implementa el FileSystem bajo S3A
valor: org.apache.hadoop.fs.s3a.S3AFileSystem
fs.s3a.path.style.access habilita o deshabilita el acceso basado en ruta
valor: true (para habilitarlo)
fs.s3a.signing-algorithm habilita o deshabilita SSL
valor: S3SignerType (para deshabilitar cifrado y mejorar el rendimiento)
Una cosa muy importante a tener en cuenta es que el cliente desde donde se lanzan los jobs que direccionan a un almacén de objetos S3 en StorageGRID tiene que tener la hora correctamente sincronizada, de lo contrario tendremos errores de acceso inesperados.
Ejemplo en Hortonworks HDP 3.x
En el “Custom Core-Site” de la configuración del servicio HDFS añadimos los parámetros anteriores. Para ello vamos a
HDFS > CONFIGS > ADVANCED > Custom core-site
y añadimos y reiniciamos el servicio HDFS y sus dependientes (nos lo pedirá):
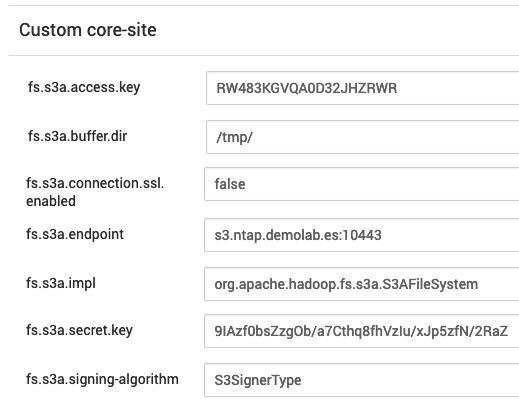
Y comprobamos:
$ hdfs dfs -ls -h s3a://datasets/airlines/airline_data
Found 3 items
drwxrwxrwx - raul raul 0 2020-09-09 21:52 s3a://datasets/airlines/airline_data/Year=2017
drwxrwxrwx - raul raul 0 2020-09-09 21:52 s3a://datasets/airlines/airline_data/Year=2018
drwxrwxrwx - raul raul 0 2020-09-09 21:52 s3a://datasets/airlines/airline_data/Year=__HIVE_DEFAULT_PARTITION__
Y probamos a hacer una copia de HDFS a S3 de StorageGRID:
[raul@hark-edge01 ~]$ hadoop distcp -skipcrccheck -direct /datasets/reddit/ s3a://datasets/reddit/
...
20/09/25 22:36:19 INFO mapreduce.Job: map 0% reduce 0%
20/09/25 22:36:30 INFO mapreduce.Job: map 40% reduce 0%
20/09/25 22:36:31 INFO mapreduce.Job: map 80% reduce 0%
20/09/25 22:36:32 INFO mapreduce.Job: map 100% reduce 0%
Ejemplo en Cloudera CDH 6.x
La configuración es similar a la anterior, con las particularidades de Cloudera Manager: en la pestaña de CONFIGURACIÓN del servicio HDFS tecleamos “core-site” en el cuadro de búsqueda y nos aparecerá la opción “Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml”. Añadimos los parámetros anteriores:
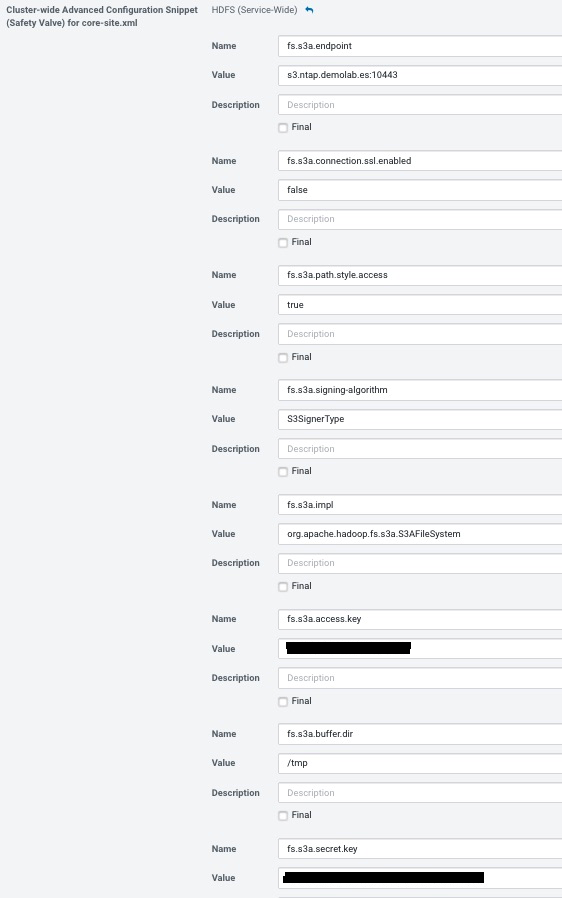
Salvar los cambios, reiniciar los servicios y desplegar la configuración de los clientes de nuevo. Con esto se habría configurado YARN, MapReduce y Spark para acceder a S3 de StorageGRID.
Si queremos utilizar S3 de StorageGRID con Hive, Impala y Hue debemos de configurar el conector S3. Para ello añadimos las credenciales de autenticación por clave de acceso desde ADMINISTRACIÓN > External Accounts :
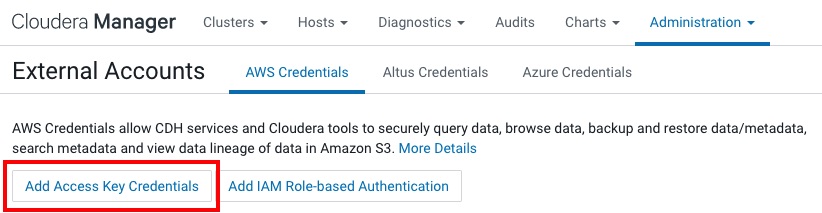
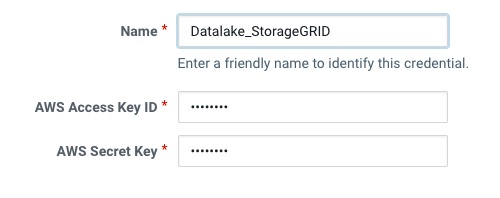
Añadimos las credenciales y le asignamos un “friendñy name”:
A continuación seleccionamos la opción para habilitarlo en nuestro clúster:

Se nos abrirá un asistente. Al terminar tendremos añadido el contector de S3 y lo único que será necesario es especificar el endpoint de S3:
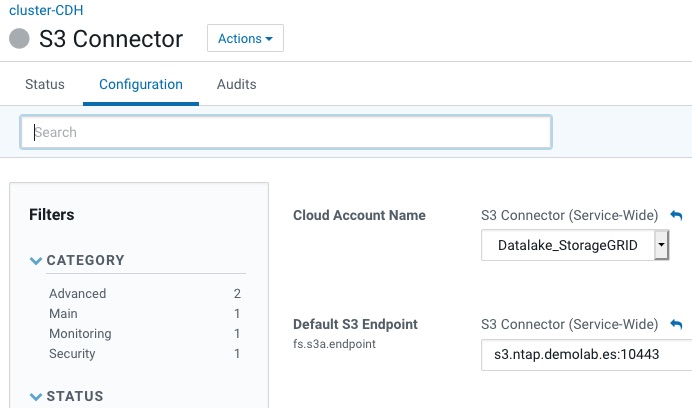
Utilizando los Committers de S3
Uno de los problemas que aparecen al utilizar Hadoop y Spark con S3 es la manera en la que se persisten los resultados al almacenamiento: durante la ejecución de un trabajo que salva cierto contenido de unas consultas a disco los resultados de las distintas tareas que conforman el trabajo se van almacenando en subdirectorios que, en la fase final, serán renombrados a su destino final. Uno de los motivos para este comportamiento es el de permitir la ejecución especulativa que por defecto está activada en MapReduce (mapreduce.map.speculative=true y mapreduce.reduce.speculative=true) y poder así gestionar de manera elegante fallos en tareas o trabajos o incluso mejorar el rendimiento en algunas ocasiones (en Spark, el spark.speculationestá fijado a false por defecto).
Esta lógica está pensada para un sistema de ficheros, pero S3 es un almacén de objetos y no un filesystem; la operación “rename” no es natural y ha de ser emulada por el cliente S3A mediante secuencias de copia y borrado, lo que, además de ineficiente, presenta problemas de rendimiento por no hablar de los problemas derivados de la “consistencia eventual” de Amazon S3 (que StorageGRID no presenta) o del hecho de que no hay nada que prevenga que otro proceso intente renombrar al mismo tiempo.
Por suerte, los Committers de S3 están aquí para arreglar la situación y utilizar mecanismos específicos que además mejoran el rendimiento al utilizar los multipart-uploads de S3 en cada una de las tareas retrasando su commit hasta la fase final del job.
Para obtener más información sobre este problema y el funcionamiento de los Committers echar un vistazo a éste enlace y a éste.
¿Cómo utilizar el Committer S3 en Hortonworks?
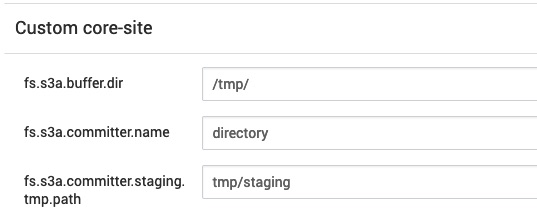
Habilitamos el committer “Directory” en Ambari, para ello editamos el “Custom Core-Site” de la configuración del servicio HDFS cmo hicimos anteriormente y añadimos
fs.s3a.committer.name = directory
fs.s3a.buffer.dir = /tmp (deberíamos de tenerlo ya configurado del paso anterior)
fs.s3a.committer.staging.tmp.path = tmp/staging (un directorio en HDFS o NFS donde salvar los uploads temporales pendientes)
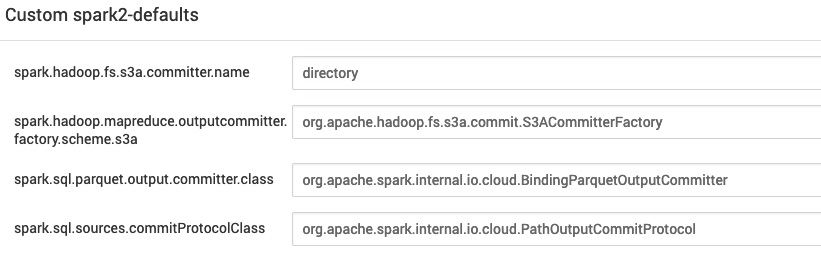
Adicionalemente, habilitamos el committer “Directory” en Spark para utilizarlo con Spark SQL, Datasets y Dataframes, editando el spark-defaults.conf y añadiendo los siguientes parámetros:
spark.hadoop.fs.s3a.committer.name = directory
spark.sql.sources.commitProtocolClass = org.apache.spark.internal.io.cloud.PathOutputCommitProtocol
spark.sql.parquet.output.committer.class = org.apache.spark.internal.io.cloud.BindingParquetOutputCommitter
spark.hadoop.mapreduce.outputcommitter.factory.scheme.s3a = org.apache.hadoop.fs.s3a.commit.S3ACommitterFactory
Si todo funciona bien y se utiliza el Committer el fichero _SUCCESS que se genera no debería de tener contenido cero sino que debería de contener un JSON con la descripción del committer que se utilizó.
[raul@hark-edge01 ~]$ hdfs dfs -cat s3a://datasets/airlines/resultado2020-12-8-16337/_SUCCESS
{
"name" : "org.apache.hadoop.fs.s3a.commit.files.SuccessData/1",
"timestamp" : 1607434903308,
[...]
¿Cómo utilizar el Committer S3 en Cloudera?
Al igual que en el paso anterior editamos el “Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml” y añadimos lo siguiente:
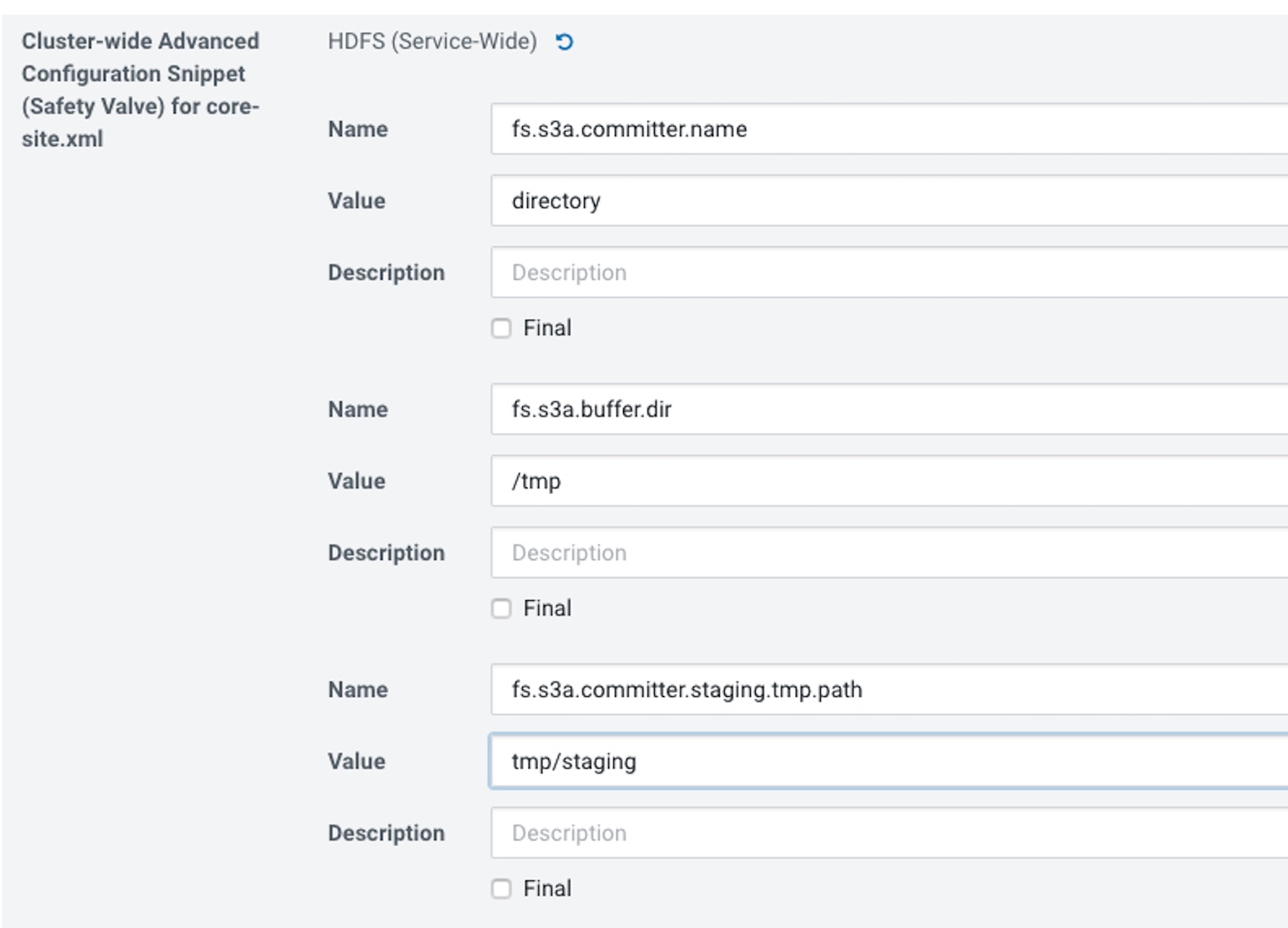
Algunos parámetros adicionales de optimización
Con StorageGRID es posible aumentar el número de threads tanto del Committer como en el propio cliente S3A ya que, dependiendo de lo grande que sea el clúster y el grid, los valores por defecto de estos parámetros pueden resultar pequeños. Hay que tener en cuenta que no hay una regla fija para estos parámetros, que dependerán principalmente del número de nodos en el clúster y de la cantidad de memoria y capacidad de proceso de los mismos. La recomendación es probar distintos valores y reajustar.
fs.s3a.threads.max el número de hilos para operaciones de upload u otra operación encolada. Por defecto es 10 y puede ser interesante subirlo a 64 y probar.
fs.s3a.connection.maximum el número de conexiones HTTP disponibles para el pool del cliente S3A. Por defecto es 10 y puede ser interesante subirlo a 200 o incluso más con StorageGRID y probar.
fs.s3a.committer.threads el número de hilos dedicados a los Committers para paralelizar operaciones. Por defecto es 8 y puede ser interesante subirlo a 32 o 64 y probar para ir ajustando. Es importante que este número siempre sea igual o inferior que el valor de “fs.s3a.threads.max”.
fs.s3a.fast.upload permite almacenar temporalmente los bloques que conforman el UPLOAD a memoria con el fin de mejorar el rendimiento en este tipo de operaciones. Por defecto suele estar deshabilitado, pero para un grid de StorageGRID que es capaz de ofrecer alto rendimiento es altamente recomendable activarlo dejándolo a true.
fs.s3a.fast.upload.buffer permite especificar qué tipo de buffer de memoria queremos utilizar. Por defecto es “disk” y se utiliza el directorio especificado en “fs.s3a.buffer.dir”, pero según lo visto en el parámetro anterior conviene almacenarlo en memoria. Hay dos tipos de buffers de memoria que se pueden utilizar, utilizar el heap de la JVM (valor “array”) o utilizar una región no perteneciente al heap de la JVM (varlo “bytebuffer”). Probar con bytebuffer y tener en cuenta que si si tenemos muchos threads corriendo en paralelo o hemos incrementado el valor de “fs.s3a.fast.upload.active.blocks” podemos quedarnos sin memoria en los ejecutores y nos fallarán tareas.