
Este post es una continuación del anterior, en el que se detalló una de las posibilidades para poder ejecutar código contra un clúster de Spark desde Notebooks de Jupyter. En este post vamos a ver una aproximación más abierta utilizando Apache Livy y SparkMagic.
To read a (bad) English Google-translated version of this post click here.
La aproximación más versátil para ejecutar código interactivo desde un Notebook de Jupyter en un clúster de Apache Spark es utilizar Livy, la API REST de Apache Spark.
![]()
Gracias a Livy es posible interactuar con un clúster de Spark a través de un interface REST, con lo que no es necesario tener instalado el cliente de Spark en el nodo o estación de trabajo desde donde se ejecuta el Notebook de Jupyter. Esto permite que prácticamente cualquier aplicación móvil o web pueda enviar trabajos o código Python o Scala a un clúster de Spark para su procesamiento sin necesidad de tener que adaptar el código.
La arquitectura de Livy es la siguiente:
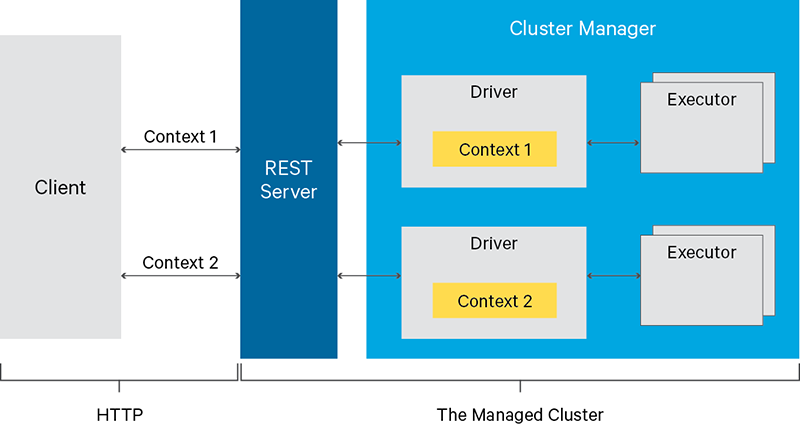
Fuente: https://livy.incubator.apache.org
Para que un Notebook de Jupyter pueda actuar como cliente del servidor REST de Livy de manera simple y sencilla es necesario que el Notebook se apoye en un componente adicional que implemente las llamadas y herramientas para poder interactuar con servidor REST de Livy. Este componente es SparkMagic.
Gracias a SparkMagic podremos ejecutar código contra un clúster de Spark directamente dentro de un kernel de IPython, o bien cargar un kernel PySpark (Python) o Spark (Scala) directamente en el Notebook y desde ahí conectarnos al clúster remoto de Spark e interactuar.
La arquitectura completa de la aproximación que seguiremos en este post es la siguiente:
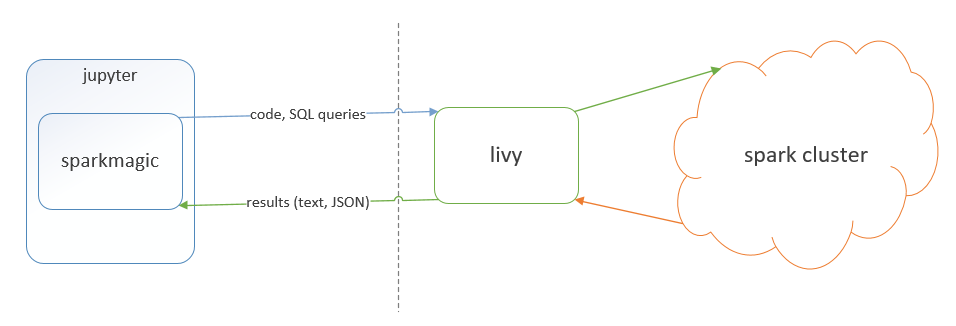
Fuente: https://github.com/jupyter-incubator/sparkmagic
Manos a la obra:
PASO 1: Instalar y configurar Livy en el clúster de Spark
Es un paso que, dependiendo de la distribución que se use, puede resultar muy sencillo. Aquí dejo algunos enlaces:
- La documentación para Hortonworks está en este enlace.
- Para instalar Livy en Cloudera hay que compilarlo y configurarlo siguiendo las instrucciones de este otro enlace.
- Los pasos para entornos Azure HDInsights están aquí.
- La página de Anaconda Enterprise tiene también unas instrucciones muy completas.
- Para más detalles referirse a la documentación oficial de Apache Livy.
Mi entorno está formado por un clúster Hortonworks HDP 3.1.5 y durante su instalación solo he tenido que indicar que se instale el servicio Livy sobre el nodo o los nodos correspondientes. Por defecto no utilizaré autenticación ni ningún tipo de seguridad por lo que fijaré livy.server.csrf_protection.enabled a false. Además activaré la suplantación de identidad (impersonation) de manera que los trabajos o el código que se ejecute contra el clúster se hará bajo el usuario “livy”. Si esto no es lo deseado, consultar los enlaces a la documentación del párrafo anterior para configurar autenticación con Kerberos, etc.
Estos son los parámetros que estoy utilizando:
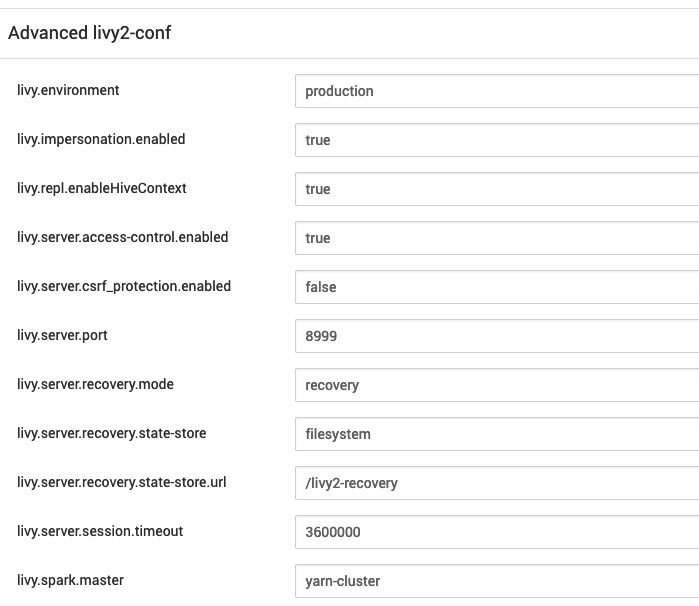
El siguiente paso es comprobar que el servicio de la REST API de Livy está disponible; para ello abrimos un navegador y apuntamos a la IP del nodo donde se ha instalado Livy utilizando el puerto especificado en la configuración:
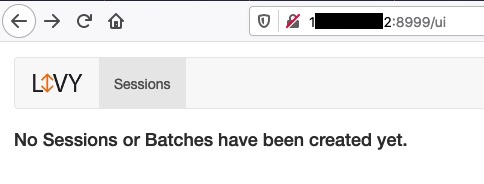
Alternativamente podemos utilizar CURL:
$ curl 10.2.1.22:8999/sessions
{"from":0,"total":0,"sessions":[]}
Probamos a crear una sesión, para ello:
$ curl -X POST --data '{"kind": "pyspark"}' -H "Content-Type: application/json" -H "X-Requested-By: Raul" 10.2.1.22:8999/sessions
{"id":23,"appId":null,"owner":null,"proxyUser":null,"state":"starting",
"kind":"pyspark","appInfo":{"driverLogUrl":null,"sparkUiUrl":null},
"log":["stdout: ","\nstderr: ","\nYARN Diagnostics: "]}
Y comprobamos en el UI del servidor Livy:
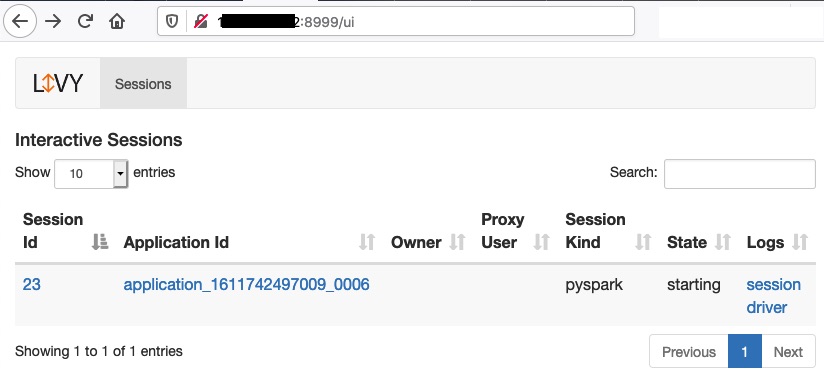
Ahora ejecutamos código en la sesión de Spark:
$ curl http://10.2.1.22:8999/sessions/23/statements -H "X-Requested-By: Raul" -X POST -H 'Content-Type: application/json' -d '{"code":"print(\"Hola mundo\")"}'
{"id":0,"code":"print(\"Hola mundo\")","state":"waiting","output":null,"progress":0.0}
Y comprobamos en el UI del servidor Livy:
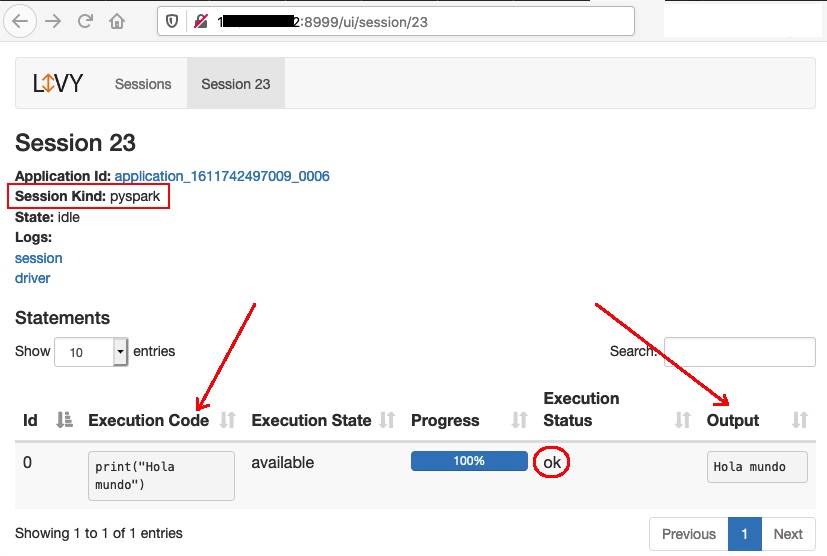
Livy ya estaría listo.
PASO 2: Instalar y configurar SparkMagic en el nodo de JupyterLab
Si tenemos instalado Conda o Anaconda seguimos estos pasos (en caso contrario utilizamos pip, por ejemplo):
Instalamos SparkMagic y su widget o extensión para los Notebooks de Jupyter:
$ conda install nodejs sparkmagic
$ jupyter nbextension enable --py --sys-prefix widgetsnbextension
Enabling notebook extension jupyter-js-widgets/extension...
- Validating: OK
Instalamos los kernels de Spark para Python, Scala y R:
$ jupyter-kernelspec install $(pip show sparkmagic | grep Location | cut -d" " -f2)/sparkmagic/kernels/sparkkernel --user
[InstallKernelSpec] Installed kernelspec sparkkernel in /home/raul/.local/share/jupyter/kernels/sparkkernel
$ jupyter-kernelspec install $(pip show sparkmagic | grep Location | cut -d" " -f2)/sparkmagic/kernels/pysparkkernel --user
[InstallKernelSpec] Installed kernelspec pysparkkernel in /home/raul/.local/share/jupyter/kernels/pysparkkernel
$ jupyter-kernelspec install $(pip show sparkmagic | grep Location | cut -d" " -f2)/sparkmagic/kernels/sparkrkernel --user
El siguiente paso es configurar SparkMagic para que apunte al servidor Livy de Spark.
Para ello nos descargamos el fichero de configuración de ejemplo de aquí y lo copiamos a ~/.sparkmagic/config.json modificándolo para adaptarlo a nuestro entorno:
$ mkdir -p ~/.sparkmagic
$ cd ~/.sparkmagic
$ wget https://raw.githubusercontent.com/jupyter-incubator/sparkmagic/master/sparkmagic/example_config.json
$ cp example_config.json config.json
$ vi config.json
{
"kernel_python_credentials" : {
"username": "",
"password": "",
"url": "http://10.2.1.22:8999",
"auth": "None"
},
"kernel_scala_credentials" : {
"username": "",
"password": "",
"url": "http://10.2.1.22:8999",
"auth": "None"
},
"kernel_r_credentials": {
"username": "",
"password": "",
"url": "http://10.2.1.22:8999"
},
Por último habilitamos la extensión:
$ jupyter serverextension enable --py sparkmagic
Enabling: sparkmagic
- Writing config: /home/raul/.jupyter
- Validating...
sparkmagic 0.17.1 OK
Test final:
Abrimos un nuevo Notebook con un kernel de PySpark y probamos:
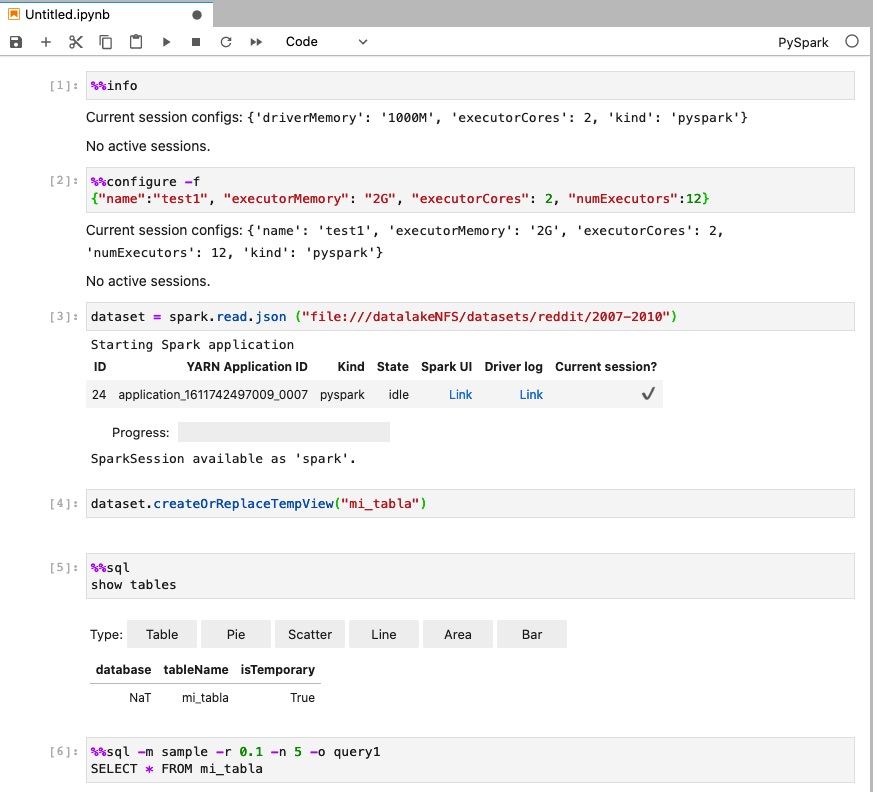
En este enlace se pueden encontrar varios ejemplos de uso.