
Este post es una continuación del anterior, en el que describí cuales son las motivaciones y beneficios de utilizar una solución empresarial como ONTAP de NetApp para Big Data Analytics e Inteligencia Artificial, así que aquí vamos a ver cómo utilizar NFS de ONTAP como almacenamiento de datos para entornos Hadoop y Spark.
To read a (bad) English Google-translated version of this post click here.
¿NFS como almacenamiento directo en Hadoop y Spark?¿En sério?
Probablemente al lector esto le pueda parecer una idea un tanto extraña ya que la primera impresión es que NFS no parece ser un protocolo de almacenamiento de alto rendimiento y, además, incluso en algunos foros especializados ha sido denostado utilizando razonamientos inapropiados, obsoletos realmente si consideramos el actual estado del arte de las tecnologías de redes y comunicaciones (en mi anterior post trato este tema específicamente).
Lo primero que tenemos que saber es que el acceso a un filesystem NFS en ONTAP desde Hadoop MapReduce o Spark es perfectamente posible al utilizar la clase FileSystem, y más en concreto la sub-clase LocalFileSystem, que implementa el acceso a un sistema de ficheros genérico en un disco local (y que tradicionalmente se había utilizado para instancias pequeñas o de test para Hadoop y Spark).
Para utilizar esta clase y poder acceder a cualquier conjunto de datos que se encuentre en el LocalFileSystem se utiliza el URI de tipo file:///, y lo único que es necesario es asegurarse de que hay una copia del conjunto de datos en cada nodo worker. Esto último, gracias a NFS, es muy simple: basta con montar el filesystem remoto en cada uno de los nodos worker sobre el mismo punto de montaje.
¿Y qué hay de la “localidad” del dato?
Los interfaces de localización seguirán funcionando igual y, aunque no se utilizan las réplicas de bloques como ocurre en HDFS para aumentar el paralelismo, todos los bloques y ficheros están “igual de cerca” del worker.
Otra de las ventajas es que NFS no tiene un modelo de coherencia simple como HDFS (un solo escritor/múltiples lectores) ni un modo “WORM relajado” donde una vez que un fichero es creado, escrito y cerrado no puede ser modificado excepto por apéndices o truncados. Así que es bastante mas flexible y tiene menos limitaciones y penalizaciones de rendimiento en operaciones de escritura, modificaciones y sobreescritura, que en el caso de ONTAP siempre serán consistentes.
Además, tanto NFSv3 como NFSv4, según sus correspondientes RFC-1813 y RFC-7530 del IETF, permiten también el acceso a los datos contenidos en un fichero a partir de un deterinado offset o desplazamiento, o entre un determinado rango de bytes, tanto en modo lectura como en modo escritura, o incluso para crear o eliminar bloqueos.
Todo esto significa que incluso un único fichero en NFS puede ser procesado en paralelo por todos los workers, especialmente cuando el formato del mismo permite la divisibilidad, es decir, su formato permita su particionado (en líneas, en caracteres específicos, etc.), como ocurre con ficheros de texto, JSON, CSV, etc. Así, por ejemplo, si se quiere procesar un fichero JSON entonces su contenido se particionará y cada ejecutor accederá su parte asignada, según muestra la siguiente imagen (los pares “clave”:”valor” están separados por una coma dentro de un fichero con formato JSON):
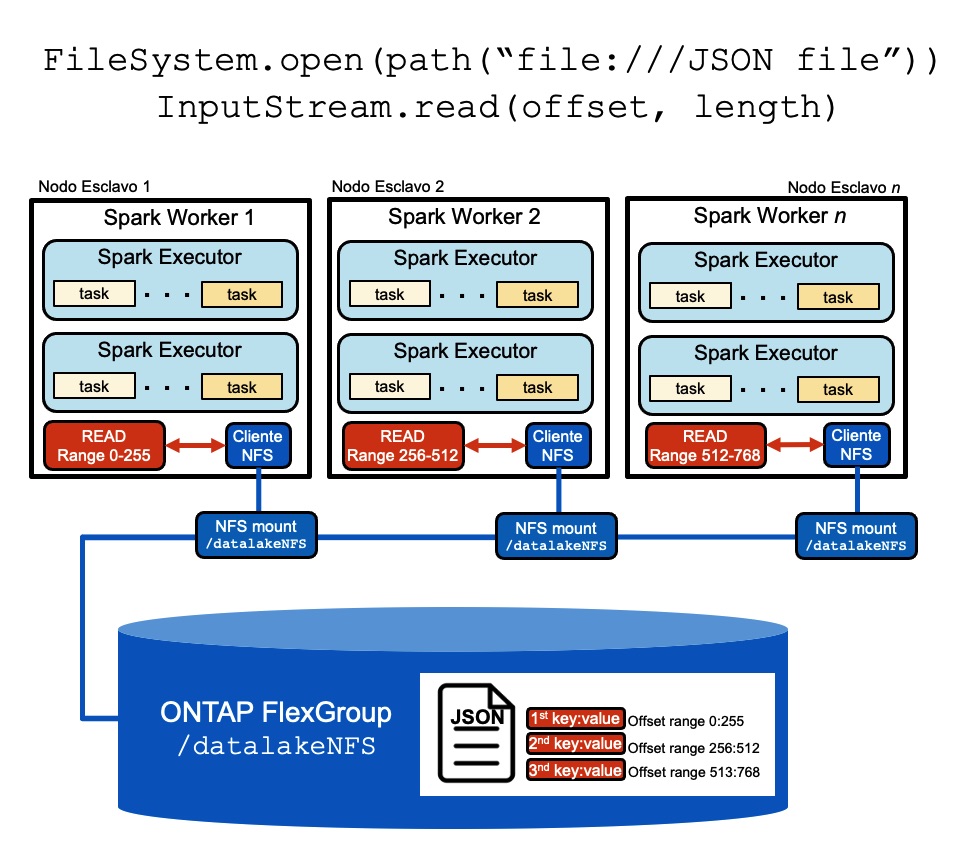
Veamos un ejemplo práctico en el que leemos un único fichero JSON desde un filesystem NFS en ONTAP en un clúster de Hadoop/Spark formado por varios nodos worker donde se encuentra montado el filesystem bajo el mismo punto de montaje (/datalakeNFS):
[raul@hark-edge01 ~]$ ls -lah /datalakeNFS/datasets/reddit/2015
total 32G
drwxrwxr-x 2 raul hadoop 4,0K nov 22 09:46 .
drwxrwxr-x 5 raul hadoop 4,0K nov 21 19:59 ..
-rw-r--r-- 1 raul hadoop 32G jul 9 2015 RC_2015-05.json
Desde una shell de spark ejecutamos lo siguiente:
[raul@hark-edge01 ~]$ spark-shell --executor-memory 2G --num-executors 32
Spark context available as 'sc' (master = yarn, app id = application_1606288386210_0015).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.2.3.1.4.0-315
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_112)
scala> import spark.implicits._
scala>
scala> val dataset_JSON_NFS = spark.read.json ("file:///datalakeNFS/datasets/reddit/2015")
[Stage 0:======================================================>(250) / 250]
dataset_JSON_NFS: org.apache.spark.sql.DataFrame = [archived: boolean, author: string ... 20 more fields]
scala>
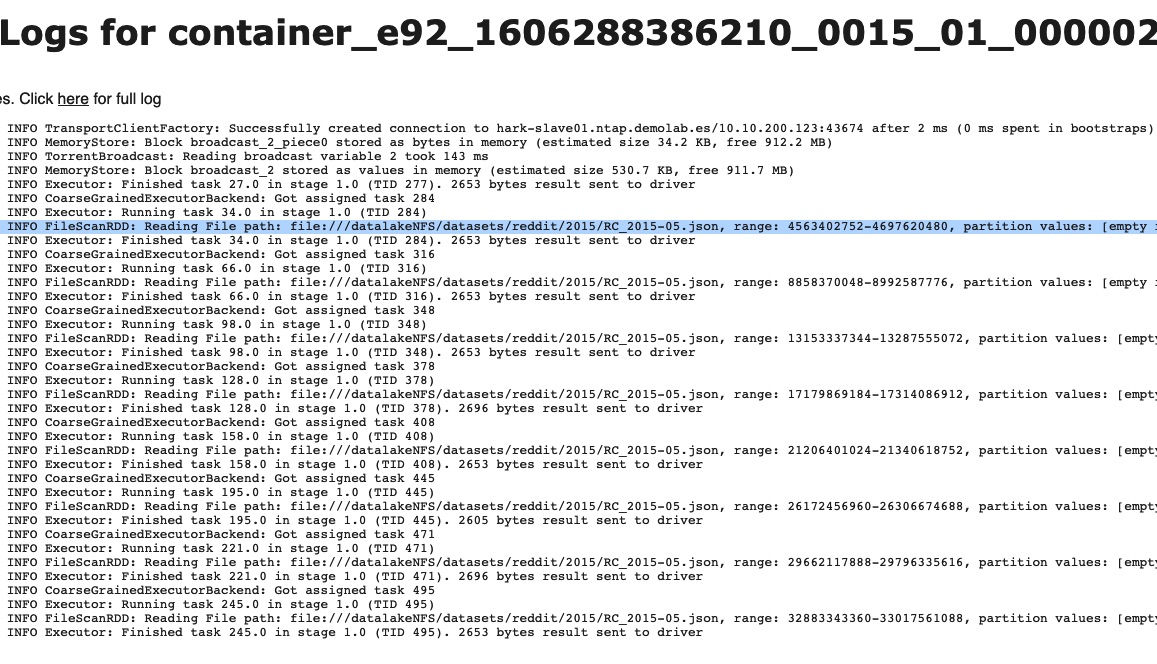
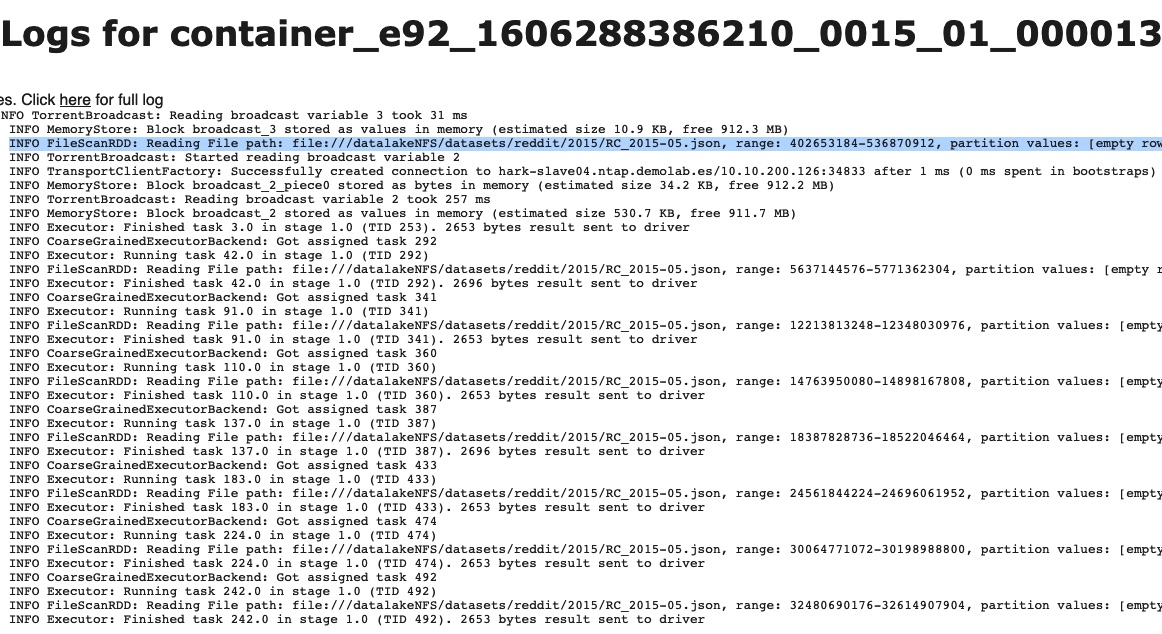
Si echamos un vistazo a las métricas de los 32 ejecutores que se han empleado para leer el conjunto de datos podemos corroborar lo anterior:
¿Cómo se configura?
Según se ha comentado antes hay que montar el filesystem NFS bajo el mismo punto de montaje en todos los nodos workers por igual.
Generalmente serán los nodos NodeManagers (que también correrán el DataNode) en Hadoop y Spark bajo YARN o los Workers (Spark Standalone, Spark K8s, etc.). Si además utilizamos un nodo frontera y ejecutamos el driver de Spark desde ahí (es decir, --deploy-mode client) en lugar de lanzar el driver en modo cluster desde cualquiera de los nodos workers, tendremos que montar el filesystem NFS igualmente bajo el mismo punto de montaje.
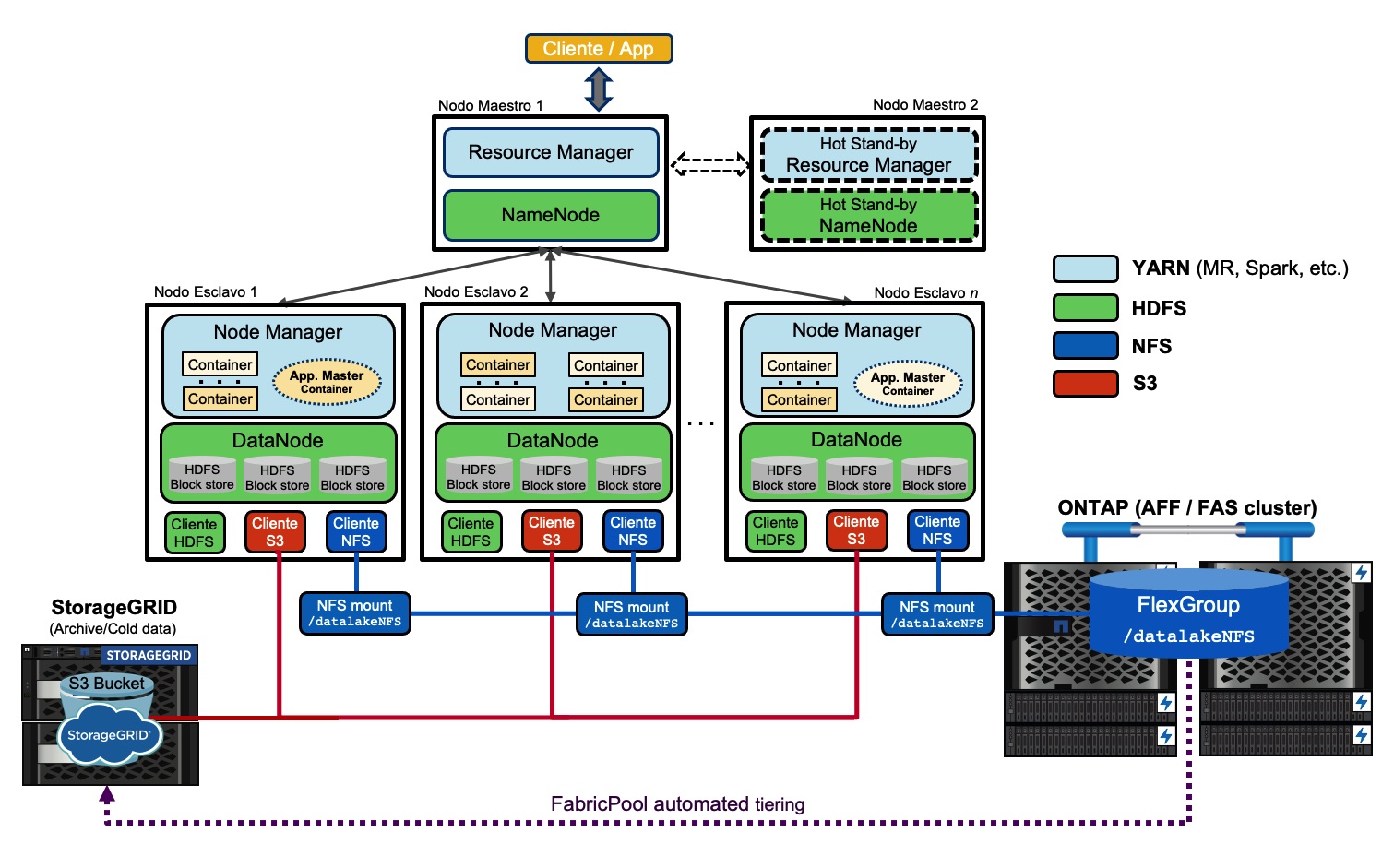
En un despliegue de Spark bajo YARN en Hadoop la arquitectura global con NetApp como solución de almacenamiento podría ser algo como esto (haz clic en la imagen para verla a tamaño adecuado en una nueva ventana):
En un despliegue puramente de Spark (stand-alone, K8s) la arquitectura global con NetApp como solución de almacenamiento podría ser algo como esto (haz clic en la imagen para verla a tamaño adecuado en una nueva ventana):
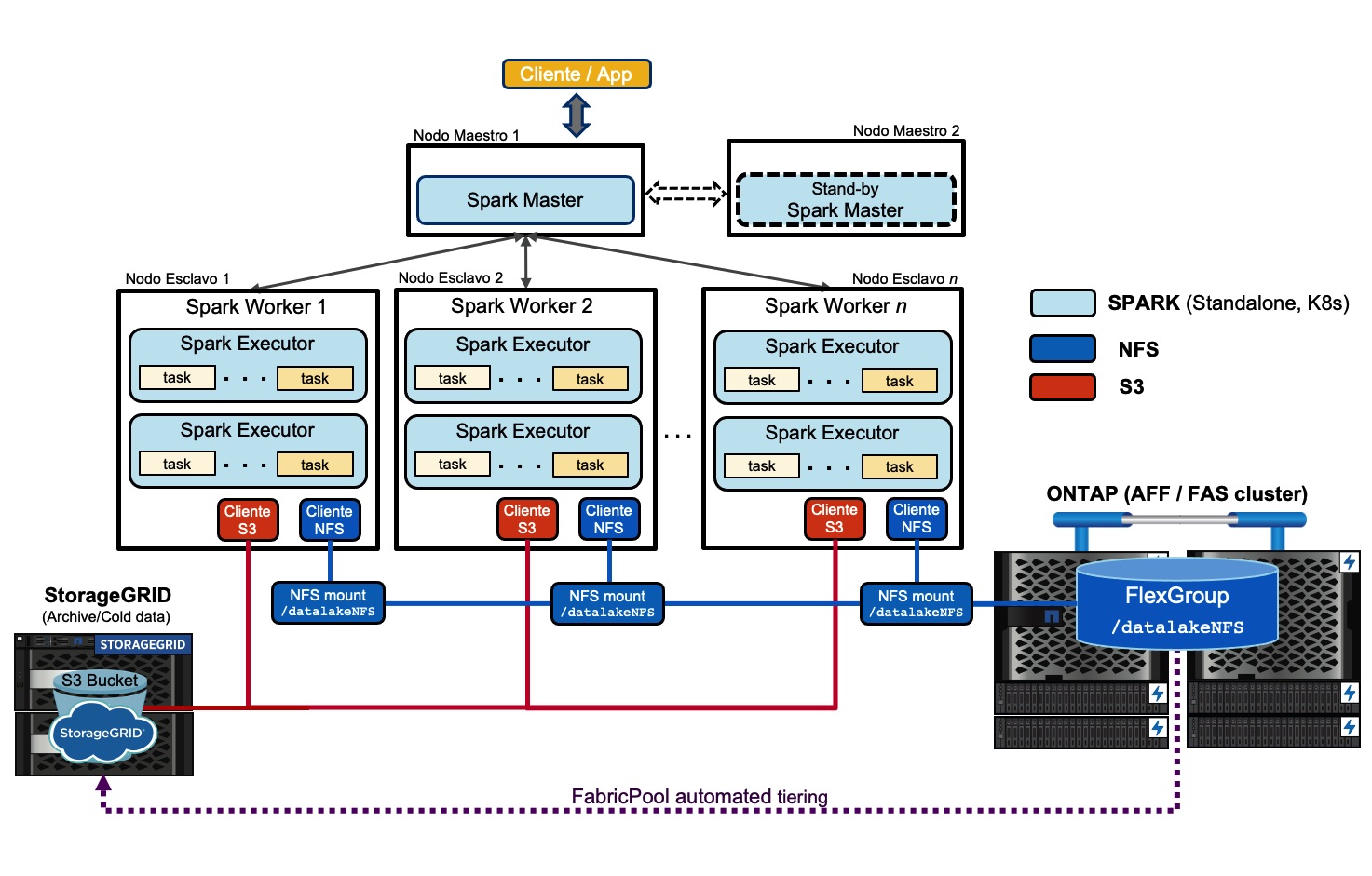
Para ello creamos el mismo directorio donde montaremos el filesystem NFS en todos los nodos esclavos:
# for i in {1..4}; do ssh hark-slave0$i mkdir /datalakeNFS; done
Y montamos el filesystem:
# for i in {1..4}; do ssh hark-slave0$i mount 10.10.200.11$i:/datalake /datalakeNFS; done
Si en el SVM en ONTAP está activado NFS v4.1 entonces los clientes negociarán la versión a pNFS (v4.1) y con un tamaño de lectura y escritura de 64KB:
# cat /proc/mounts | grep datalake
10.10.200.111:/datalake /datalakeNFS nfs4 rw,relatime,vers=4.1,rsize=65536,wsize=65536,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,local_lock=none
Si quisiésemos utilizar NFS v3 entonces añadimos -o vers=3 como opción de montaje.
Por último ya solo necesitamos apuntar al dataset utilizando el URI file:/// como se ha mencionado anteriormente:
$ spark-submit --class "MyClass" SparkApp.jar file:///mount_point/dataset_dir/
o bien desde la shell de Spark
scala> val dataset = spark.read.json ("file:///mount_point/dataset_dir/")
o alternativamente desde la shell de PySpark:
>>> dataset = spark.read.json("file:///mount_point/dataset_dir/")
También podemos hacer cosas como esta:
$ hdfs dfs -ls -h file:///datalakeNFS/datasets/reddit/2015
Found 5 items
-rw-rw-r-- 1 raul hadoop 26.7 G 2015-07-09 03:33 file:///datalakeNFS/datasets/reddit/2015/RC_2015-02.json
-rw-rw-r-- 1 raul hadoop 30.4 G 2015-07-09 03:31 file:///datalakeNFS/datasets/reddit/2015/RC_2015-03.json
-rw-rw-r-- 1 raul hadoop 31.3 G 2015-07-09 03:36 file:///datalakeNFS/datasets/reddit/2015/RC_2015-04.json
-rw-rw-r-- 1 raul hadoop 31.2 G 2015-07-09 03:25 file:///datalakeNFS/datasets/reddit/2015/RC_2015-05.json
Algunas recomendaciones basadas en mi experiencia
A partir de la versión 9.7 de ONTAP la tecnología de FlexGroup tiene bastantes mejoras, incluyendo las heurísticas de ingesta y soporte para pNFS, que la convierten en una candidata ideal para entornos de Big Data. Basándome en mi experiencia, estas son una série de recomendaciones:
-
Utilizar un FlexGroup con el suficiente número de constituents para permitir el escalado horizontal futuro y conseguir una adecuada utilización de todos los recursos disponibles entre todos los nodos del clúster de ONTAP.
-
Utilizar NFS v4.1 (pNFS) y crear, al menos, dos LIFs por nodo en el clúster de ONTAP (dependiendo del número de puertos, su posible agregación y ancho de banda disponible). Realizar los montajes del filesystem NFS de ONTAP (el FlexGroup) utilizando los distintos LIFs disponibles para balancear los accesos (por ejemplo, el nodo worker01 que monte utilizando el LIF-01, el worker02 que utilice el LIF-02 para montar, y así sucesivamente).
-
Aumentar el tamaño máximo de transferencia para NFS en el SVM de ONTAP que sirve el FlexGroup a 256KB, será necesario re-montar el filesystem en los clientes NFS y éstos re-negociarán el tamaño máximo automáticamente. Para ello ejecutar
set advanced; nfs modify -vserver <vserver_name> -tcp-max-xfer-size 262144; set admindesde la shell de ONTAP. El tamaño máximo puede ampliarse hasta 1MB (1048576 bytes), pero generalmente 256KB suele ofrecer el mejor ratio rendimiento/latencia según las pruebas que he realizado. -
La tecnología de FlexGroup permitirá obtener mejor rendimiento si el conjunto de datos almacenado está formado por varios ficheros, generalmente un número divisible entre 8 y 16 (según el número de constituents), aunque si el número de ficheros es muy elevado tampoco tendrá mucha trascendencia. Un ejemplo sencillo y algo extremo: es mejor almacenar un conjunto de datos en 8 ficheros de 128MB cada uno que en un único fichero de 1GB.
Consideraciones con NFS versión 4
Hay que tener en cuenta que el ‘‘Domain ID’’ de NFSv4 debe de tener el mismo valor en todos los nodos así como en el SVM de ONTAP.
Para ello nos aseguramos de que el parámetro Domain = en el /etc/idmapd.conf de todos los nodos worker es el mismo. De la misma manera, en el SVM de ONTAP fijamos el ‘‘Domain ID’’ de NFSv4 mediante el comando nfs modify -vserver <vserver_name> -v4-iddomain <domain_name> o bien lo cambiamos en el GUI (System Manager).
Además el “User_ID” y el “Group_ID” de los usuarios y grupos de nuestro entorno ha de ser el mismo en todos los nodos del clúster así como en el SVM. Si no utilizamos un LDAP o un NIS entonces nos tendremos que asegurar de que los UIDs y los GUIDs son iguales en todos los nodos worker del clúster revisando los ficheros /etc/group y /etc/passwd y modificando donde haga falta, teniendo en cuenta que tendremos que parar préviamente procesos o daemons y reajustar permisos en el filesystem.
En el SVM de ONTAP crearemos los usuarios y grupos mediante:
::> vserver services unix-group create -vserver <vserver_name> -name <group_name> -id <group_id>
::> vserver services unix-user create -vserver <vserver_name> -user <user_name> -id <user_id> -primary-gid <group_id>
Adicionalmente establecer el Group_ID del usuario root en el SVM a 0 con:
::> vserver services unix-user modify -vserver <vserver_name> -user root -primary-gid 0
Por último, nos aseguraremos también de que no falten cosas básicas como el paquete nfs-utils instalado en los nodos (yum install nfs-utils), o que los servicios necesarios para el funcionamiento del cliente NFS están habilitados y en ejecución:
systemctl status rpcbindsystemctl status nfs-idmapsystemctl status rpcbind.socket